PDF Text
The PDF Text plugin enables searching on PDF files uploaded to an Omeka Classic item by extracting their text layer and saving them to the file records. PDF Text ignores images and layout in the original file, leaving only searchable text.
The PDF Text plugin does not run text recognition on image-only PDFs, such as those made by scanning documents.
System requirements
PDF Text requires the pdftotext utility, which is part of the poppler-utils package. You can install it yourself from the command line:
pip install poppler-utils
You may need to contact your server administrator to install it.
PDF Text in action
- Add PDF file(s) to a new or existing item.
- Save the item.
- If the plugin is active, PDF Text will extract any text layers from the PDF(s) and input the text to the Text metadata field attached to the file (not the item).
You can view the extracted text in the admin side, on the File page, or when editing the file, on the "PDF Text" tab. On the public side, this field will show on the file display.
Note that PDF Text will fail to extract text from any PDF that contains emojis. This will result in no extracted text being saved. This will also cause an import error on CSV Import when PDF Text is working on PDF files added through the import process.
Re-process existing PDFs
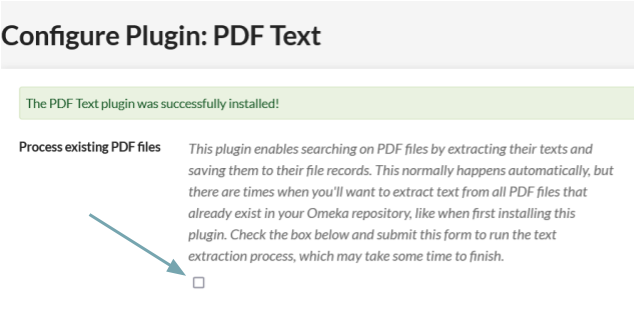
The PDF Text "Configure" page, accessible from the Plugins page, allows you to run a batch-text-extraction process on all PDF files already in your Omeka database.
Check the "Process Existing PDF files" box and then "Save Changes". This will run the text extraction process on all PDF file attachments.